mlscraper(开源的 Python 爬虫脚本)简介
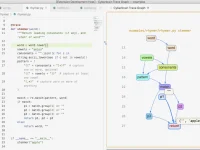
mlscraper是一个开源的 Python 爬虫脚本,能够帮助我们实现自动化网页数据抓取。使用传统的网页抓取方式需要手动指定HTML元素或CSS选择器,而mlscraper则采用了与众不同的方法。它通过用户提供少量示例数据对目标网页进行训练,自动识别数据提取规则,从而实现自动抓取结构化数据的目标,可以说是更加智能化。
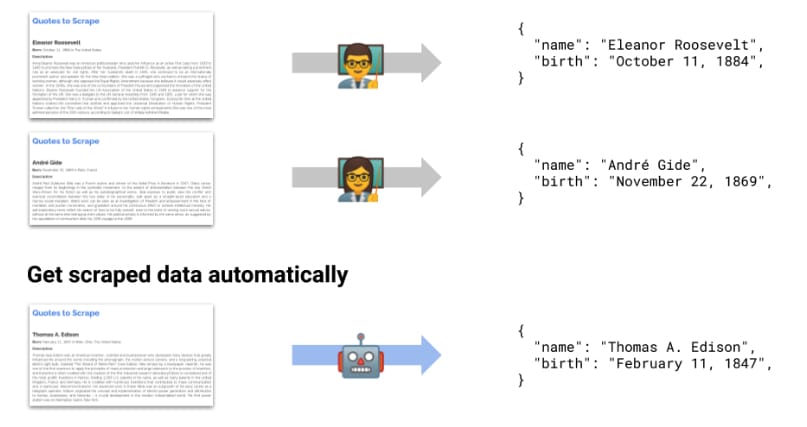
操作流程如下:
- 用户定义想要抓取的数据示例
- mlscraper在HTML DOM中查找用户的示例数据
- 确定用于数据提取的规则和方法
- 提取数据并以字典的形式返回
这个爬虫脚本的主要优点是无需手动指定选择器,只需提供少量示例数据即可自动生成抓取规则。这不仅简化了抓取过程,而且使得维护工作也变得更加容易。无论目标网页的HTML结构发生怎样的变化,这个爬虫脚本都能自动适应。