CogVideo(文字生成视频开源模型)简介
CogVideo 是一个文字生成视频开源模型,由清华大学讯飞联合实验室推出。该项目目前开源了两个视频生成模型:CogVideo(ICLR 2023)和CogVideoX系列。该模型能够根据文本输入生成相对高帧率的视频。
CogVideo 是首个开源的预训练文本到视频生成模型,能够根据文本输入生成相对高帧率的视频。
CogVideoX 则是 CogVideo 的升级版本,是清华讯飞实验室在 2024 年开源的视频生成模型系列。目前已开源了 CogVideoX-2B 和 CogVideoX-5B 两个模型,分别具有 20 亿和 50 亿参数。与 CogVideo 相比,CogVideoX 系列在生成视频质量和视觉效果方面有了大幅提升。
CogVideoX 系列在模型架构、训练策略等多方面进行了创新,例如采用了 Diffusion Model、3D Casual VAE 等先进技术。该系列模型支持量化推理,能在较低算力设备上运行,且支持英语输入和长文本输入。
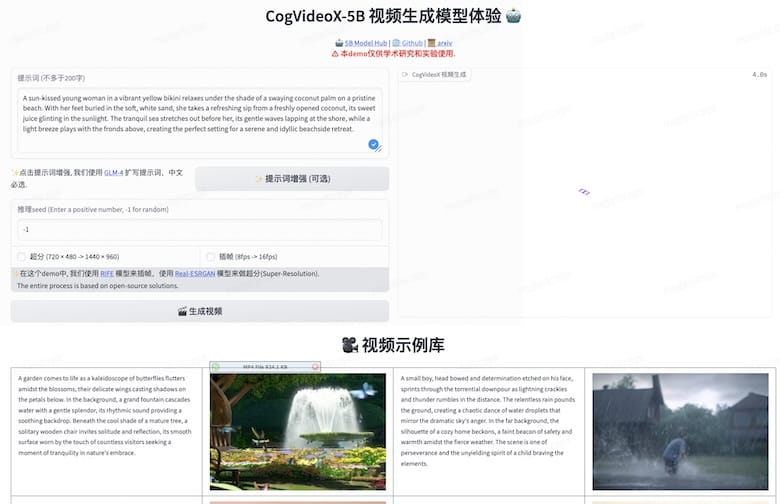
CogVideo(文字生成视频开源模型)官网
- 开源地址:https://github.com/THUDM/CogVideo
- 在线体验地址1:https://huggingface.co/spaces/THUDM/CogVideoX-5B-Space
- 在线体验地址2:https://modelscope.cn/studios/ZhipuAI/CogVideoX-5b-demo
项目提供了在线 Demo,打开在线Demo后可以输入中文描述,体验文本到视频生成效果。