AudioNotes(基于AI的音频转文字工具)简介
AudioNotes 是一个基于AI的音频转文字工具,基于 FunASR 和 Qwen2 构建,可以将音视频转换为markdown笔记。它能够快速提取音视频的内容,并调用大模型进行整理,最终生成一份结构化的 markdown 笔记,方便快速阅读和学习。
主要特点包括:
1. 音视频转文字:利用 FunASR 进行高精度的语音识别,将音视频转换为文字。FunASR 是一款由微软亚洲研究院发布的通用语音识别系统,支持多种语言和场景。
2. 内容整理:利用 Qwen2 大语言模型对提取的文字进行智能分析和结构化,生成带有大纲的 markdown 笔记。Qwen2 是一款基于 GPT-3 训练的大规模对话语言模型,具备出色的文本理解和生成能力。
3. 对话交互:用户可以与系统对话,进一步查询和学习笔记内容,系统会利用大模型给出针对性解答。
4. 部署方便:提供 Docker 一键部署和本地部署两种方式,用户可根据需求灵活选择。Docker 部署更为简单,本地部署则需要提前准备 PostgreSQL 数据库环境。
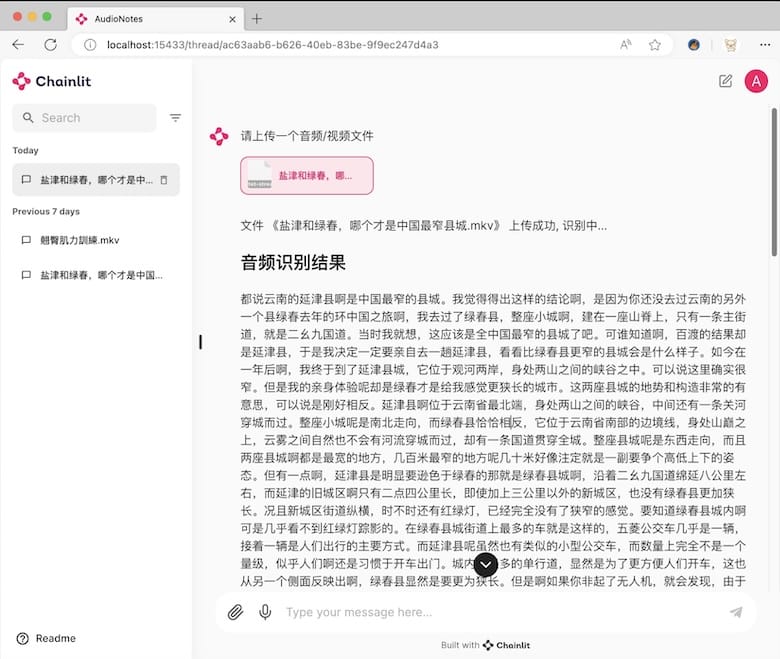
5. Web 界面:采用 Streamlit 框架构建直观友好的 Web 应用界面,用户可轻松上传音视频文件、查看生成的笔记和与系统对话。
总的来说,AudioNotes 将最新的语音识别和大模型技术相结合,为用户提供了一种高效的音视频学习方式。无需手动记笔记,系统可以自动生成结构化笔记并支持交互式学习,极大节省了笔记时间,提高了学习效率。
AudioNotes(基于AI的音频转文字工具)官网及教程
- 官网:https://github.com/harry0703/AudioNotes
1、安装 Ollama,下载对应系统的 Ollama 安装包进行安装
https://ollama.com/download
2、拉取模型:以阿里的千问2 7b 为例 https://ollama.com/library/qwen2
ollama pull qwen2:7b
3、有两种部署方式,一种是使用 Docker 部署,另一种是本地部署
Docker部署(推荐)
curl -fsSL https://github.com/harry0703/AudioNotes/raw/main/docker-compose.yml -o docker-compose.yml
docker-compose up
docker 启动后,访问 http://localhost:15433/
登录账号为 admin,密码为 admin (可以在 docker-compose.yml 文件里面修改)
本地部署
需要有可访问的 postgresql 数据库
conda create -n AudioNotes python=3.10 -y
conda activate AudioNotes
git clone https://github.com/harry0703/AudioNotes.git
cd AudioNotes
pip install -r requirements.txt
将 .env.example 重命名为 .env,修改相关配置信息
chainlit run main.py
服务启动后,访问 http://localhost:8000/
登录账号为 admin,密码为 admin (可以在 .env 文件里面修改)