
Latte(开源AI视频生成模型)简介
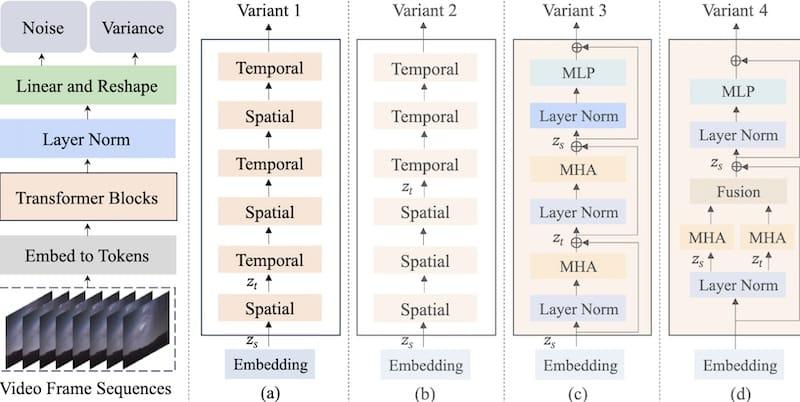
Latte是一个开源AI视频生成模型,能够让我们实现用文字生成视频,可以说是一个开源免费版的Sora,该AI模型使用的是时空块思路,一样的Diffusion Transformer,为了对从视频中提取的大量提示词进行建模,从输入视频的空间和时间维度的角度出发,引入了四种高效的变种。为了提高生成视频的质量,该模型通过严格的实验分析确定了该模型的最佳实践,包括视频剪辑补丁嵌入、模型变种、时间步类信息注入、时间位置嵌入和学习策略,在四个标准的视频生成数据集(FaceForensics、SkyTimelapse、UCF101和Taichi-HD)上实现了最先进的性能。
Latte(开源AI视频生成模型)官网
- Github项目开源主页:https://github.com/Vchitect/Latte
- 官网:https://maxin-cn.github.io/latte_project/
1、下载及设置:
git clone https://github.com/maxin-cn/Latte.git
cd Latte
2、采样
可以使用 sample.py 从预先训练的 Latte 模型中进行采样。该脚本有各种参数来调整采样步骤、更改无分类器指导尺度等。例如,要从 FaceForensics 上的模型中采样,可以使用:
bash sample/ffs.sh
如果您想尝试从文本生成视频,请下载 t2v_required_models 并运行bash sample/t2v.sh 。
3、训练
train.py 中提供了 Latte 的训练脚本。该脚本可用于训练类条件和无条件 Latte 模型。要在 FaceForensics 数据集上使用 N GPU 启动 Latte (256×256) 训练:
torchrun --nnodes=1 --nproc_per_node=N train.py --config ./configs/ffs/ffs_train.yaml
如果有一个使用 slurm 的集群,还可以使用以下脚本训练 Latte 的模型:
sbatch slurm_scripts/ffs.slurm
此外该模型还提供了视频图像联合训练脚本 train_with_img.py 。与 train.py 脚本类似,该脚本也可用于训练类条件和无条件 Latte 模型。例如,如果想在 FaceForensics 数据集上训练 Latte 模型,可以使用:
torchrun --nnodes=1 --nproc_per_node=N train_with_img.py --config ./configs/ffs/ffs_img_train.yaml








![Telegram Downloader - Telegram视频下载器[Chrome]](https://www.3kjs.com/wp-content/uploads/2025/04/iScreen-Shoter-Google-Chrome-250422093844-200x150.webp)