周四,微软研究人员宣布了一种名为VALL-E的新文本到语音 AI 模型,在给定三秒钟的音频样本时,它可以准确地模拟人的声音。一旦它学会了一种特定的声音,VALL-E 就可以合成那个人说任何话的音频——并以一种试图保持说话者情绪基调的方式进行合成。
微软将 VALL-E 称为“神经编解码器语言模型”,它建立在Meta 于 2022 年 10 月宣布的名为 EnCodec 的技术之上。与通常通过操纵波形合成语音的其他文本转语音方法不同,VALL-E 生成来自文本和声音提示的离散音频编解码器代码。它基本上分析了一个人的声音,借助 EnCodec 将该信息分解为离散的组件(称为“令牌”),并使用训练数据来匹配它“知道”的内容,如果它说出三个之外的其他短语,该声音将如何发声- 第二个样本。
- VALL-E官网:https://valle-demo.github.io/
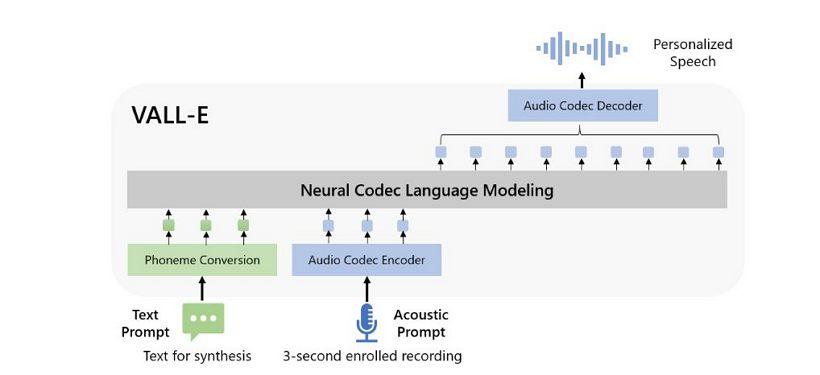
微软在一个名为LibriLight的由 Meta 组装的音频库上训练了 VALL-E 的语音合成能力。它包含来自 7000 多名演讲者的 60000 小时英语演讲,大部分来自LibriVox公共领域有声读物。为了使 VALL-E 产生良好的结果,三秒样本中的语音必须与训练数据中的语音非常匹配。
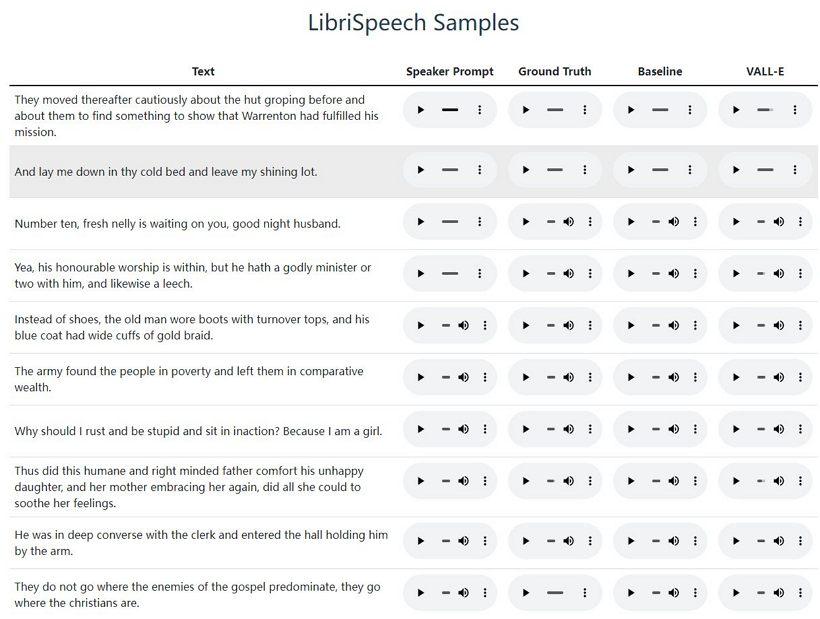
在 VALL-E示例网站上,Microsoft 提供了数十个 AI 模型的音频示例。样本中,“Speaker Prompt”是提供给VALL-E必须模仿的三秒音频。“Ground Truth”是同一位说话者说出特定短语的预先存在的录音,用于做对比。“Baseline”是传统的文本到语音合成方法提供的合成示例,“VALL-E”示例是VALL-E模型的输出。
也许是由于 VALL-E 可能助长恶作剧和欺骗的行为,微软没有提供 VALL-E 代码供其他人试验,因此我们目前还无法自行测试 VALL-E 的能力。